今天來介紹自然語言處理(英語:Natural Language Processing,縮寫作NLP),它運用了電腦科學、語言學及人工智慧三者的技術,讓機器可以讀取、學習人類說出或是寫出的語言。
下面來舉例一些常見的NLP應用:
那為了讓深度學習模型可以處理語言,通常我們會將語言轉換成數字形式。這邊簡單介紹兩種方法:獨熱編碼(one-hot encoding)與詞向量(word vector)
One-hot encoding:在NLP中one-hot encoding會記錄字詞的位置,出現的位置為1,其餘的位置為0。言外之意one-hot encoding會以非0即1的方式呈現。one-hot的做法非常簡單,但也因為這樣導致資料稀疏,沒有包含太多資訊且維度高,如果有1000個不重複的單字,矩陣就會有1000列。
舉例說明:「我有一支筆」,「這支筆是紅色」。會需要處理「我」「有」「一」「支」「筆」「這」「是」「紅色」,我們可以用矩陣來幫助我們觀察,因爲有十一個字所以應該要有11行,然後有重複兩個字,所以會是9列。
word vector:word vector會記錄詞的位置及意思,即使轉換為數字型態也具資訊。最核心想法就是每一個詞都有一個向量值,這些詞被NLP模型分類歸納在一起,比如哪些字容易跟某個特定字一起使用,當兩個詞的意思越相近,他們在向量空間中也會越靠近。想知道更多也可以上網搜尋Word2vec!
舉例說明: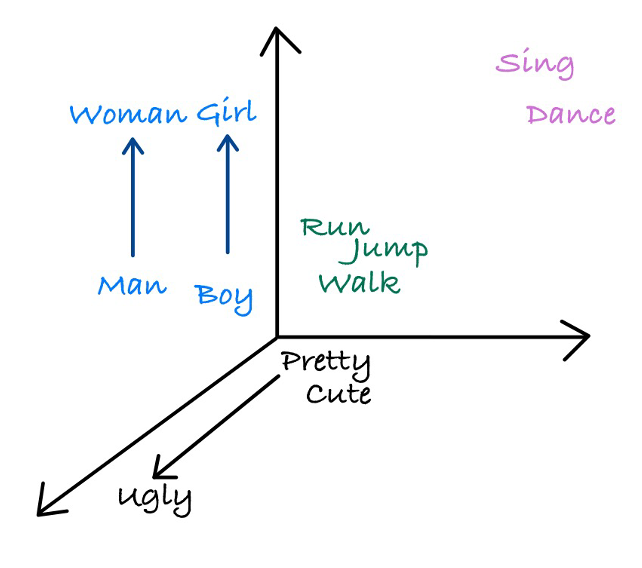
詞向量改善了one-hot encoding的缺點,發展出資訊密度高且維度少(雖然說維度少但是是跟one-hot encoding相比)此外也解決了one-hot encoding無法表達詞跟詞之間的語意關係問題。
如過你想體驗詞向量空間,趕快來試試看Word2viz 吧!(https://lamyiowee.github.io/word2viz)
今日總複習:深度學習可以從資料中萃取特徵,提供給NLP模型使用!
歡迎大家不吝嗇給予指教,那我們明天見囉~


 iThome鐵人賽
iThome鐵人賽